
Cranberry audio
Cranberry audio intro
Audio programming is conceptually simple however writing it correctly is not an easy task. So I chose to use existing libraries.
After skimming through few audio library’s(sdl, miniaudio, wwise and fmod) documentations, I decided to go with miniaudio and base my wrapper on it.
Why miniaudio?
- Open source MIT
- Thin platform wrapper
- Freedom to override any system in the library to my satisfactory.
MiniAudio notes
Device
- The device can be created with device default sampling rate, format, channel count. The
ma_device_initmethod takes care of filling these information into device. - Specify the an unit time period in milliseconds or specify frames count per period directly. This will be used together with sample rate to calculate the buffer count and size in bytes per callback required.
Engine
- The engine must be created for each unique combination of device config. So if changing device config or device, the engine and all its related object must be recreated.
- The listeners are basically for directional sounds and there can be maximum of four. Listener configs must be set after engine is created.
- The engine generates frames for a device using the sounds, data sources and listeners.
- Allocation callbacks will be used for dynamically allocating engine nodes for sound and other sub nodes. So this must not be arena with engine lifetime.
- Engine will be exposed as engine but instead of one to one. There will be only one audio engine for a world. A miniaudio engine per audio device will be encapsulated inside the one audio engine to accommodate multiple local players with separate audio devices.
Sound
- A sound node can be attached as input to another node.
- A data source sub range can be used when playing in sound.
- Data source sub range is different from looping range so I assume a single data source and sound is enough to play 3 section audio(Start-Loop-End).
- The flags can be used to specify if want to decode at play. However it is best to decode the audio before using decoder and then use it as data in data source.
- Sounds will be exposed as audio player or controller.
Data Source
- MiniAudio works with custom data source using virtual interface with C-Style virtual table.
- Uses C-Style template with type being casted to
ma_data_source_base *. So whatever type pointer is passed intoma_data_source_*functions it must havema_data_source_baseas base data/at zero offset. - Best to have raw data without encoding.
- Data source will be exposed as audio resource interface and will be created by engine assets.
Decoders
- Supported formats
- MP3
- WAV
- FLAC
- VORBIS(If including stb VORBIS source)
- Each decoder is created for a unique audio. So decoders must be created for each audio data separately.
- In our case this means just decode from memory.
- These decoders will be exposed as functions rather than as object in engine as part of
ICbeAudioModuleinterface.
Node graph
- Engine is the node graph into which all the other node graph and sounds plug into as the endpoint.
- Only difference about node graph from regular graph is each input bus index of node graph can accept several inputs. Each inputs gets mixed together. That is how several sounds or sound graphs can be plugged into the engine end point input.
Sound Groups
- These are similar to sound but with out any data. Their sole purpose is to modify the input based on config provided and it can be shared across several sounds in an engine. This allows it to be used as common settings for a group of sounds. It has all properties of sound like spatialize, pan, pitch, gain, volume etc…
Designing the engine interface
Notes on points to consider when designing the engine interface.
- In order to reduce the resampling of the audio frames and recreating data sources. The sample rate of each data source must match that of each engine. The format and channel count could differ though.
- The devices must be created with sampling rate the engine targets instead of device default. This ensures we can use the same data source for all devices and engines.
- Engine and all the sound sources must be recreated after changing the device. However there will be only one cranberry audio engine and remains the same, similar setup works for the sounds as well.
- There will be only
MAX_LOCAL_PLAYERScount of engines, So for each cranberry engine sound player there could beMAX_LOCAL_PLAYERSnumber of sounds. - In case of sound graphs I want to keep the graphs independent of the engine. Since input sound nodes are the only variable across engines and devices, custom miniaudio sound nodes must be created that fetches PCM frames from different sound based on which mini audio engine is reading the frames.
- Sound graphs must be created from some high level graph structure(Created from UI) the total number of nodes, their types and memory requirements can be precalculated. This makes it possible to not have separate node resources in Audio module interface.
- Inputs of sound graph will be the data sources/Audio resources. The audio resources themselves will contain the link to sound resource created from data source in the engine.
- Following resources must be independent of the engine/devices
Data sources/Audio resourcesSound graphs(Static portion will be engine independent however the dynamic portion must be initialized within each engine for each instance)Sound group resource(Must also have a copy per engine as the outputs has to connect to engine input bus)
- Following resources are unique to engine and must retain the create configuration.
Sound/Audio playerSound graphs(Static portion will be engine independent however the dynamic portion must be initialized within each engine for each instance)Sound group resource(Must also have a copy per engine as the outputs has to connect to engine input bus)ESoundGroupThis is similar to sound group resource but adjustable globally across all the group/sound/graph that outputs into this(Must also have a copy per engine as the outputs has to connect to engine input bus).
How sound group and ESoundGroup must be used?
General idea is
- what ever node that connect to a sound group it must either connect to
sound group resourceor connect toESoundGroupbut not to both. ESoundGroupmust be the last node output in any graph(Can be one as simple as sound and group or sound graph and group). So if used, it must be the node connecting to the input of engine. Sound, Sound graph and other sound group must connect to it.- A
Sound player resourceorSound Graphcan connect to asound group resourceorESoundGroup. Do not confuse it with sounds embedded into sound graph. - Sounds embedded inside a sound graph can only connect to other sound graph nodes. In fact none of the nodes in sound graph can connect to
sound group resourceorESoundGroupexcept the sound graph end node. - A
sound group resourcecan connect toESoundGrouponly. This is to reduce the complexity(I doubt there will be need to create such a interconnected group) with replicating the sound group across several engines.
Audio Streaming
Audio files are huge streaming is the only way to keep the memory usage in check. MiniAudio provides the opportunity to stream but only if using its resource manager.
I am not using the resource manager so I decided to use the ma_decoder directly as dynamic data source. I also want to keep using ma_audio_buffer_ref for streaming.
ma_audio_buffer_ref requires all the memory to be accessibly.
So the problem I have to solve is have the memory but not have the memory. The solution is something all the modern operating system and hardware offers Virtual allocation with place holders. That is the solution I opt for.
Here is how it works. I allocate the virtual space addresses with no backing memory for all frames necessary for an audio buffer.
This read only address we call PCM Frames address. Then comes the streaming(Writable) memory address that is mapped to physical memory, This address we call Streaming address.
This streaming address space is 64k aligned and it is used to determine how many frame an audio page will contain. On top of that I double buffer the audio page, this is to load next page asynchronously while current page plays.
Let us assume totalPhysicalMem is 8bytes and contains 2 frames, double buffering. Then the memory mapping will look like below
The totalPhysicalMem gets mapped to PCM Frames address repeatedly which the ma_audio_buffer_ref can use to read from as continuous address.
Whenever streaming new data for a frame it gets written to page range the frame belongs to in Streaming address. The ma_audio_buffer_ref could just keep reading from the PCM Frames address just like regular memory.
ma_decoder can be initialized using virtual file system using custom callbacks. Decoder calls read or seek from callback whenever it has need for some new data.
So far I have shown ways to keep ma_audio_buffer_ref fed and ma_decoder reading data. However I have not mentioned when data gets read from file or where the data gets moved to Streaming address.
It happens like this. I override the default VTable ma_audio_buffer_ref’s data source uses for reading/seeking frame data. When the audio buffer tries to read a frame I make sure that frame is ready in the PCM Frames address by either waiting for async task streaming the data. Or block stream the data into Streaming address. Then issue new async request to stream in next audio page as audio mostly gets played forward in games(Reverse might block when streaming but that is okay). Now that data request is made by ma_audio_buffer_ref loading is where ma_decoder comes in. The audio data will be stored in some encoded format, so any kind loading must go through a decoder. The decoder uses the vfs virtual table to stream data from whatever source audio lib caller provides.
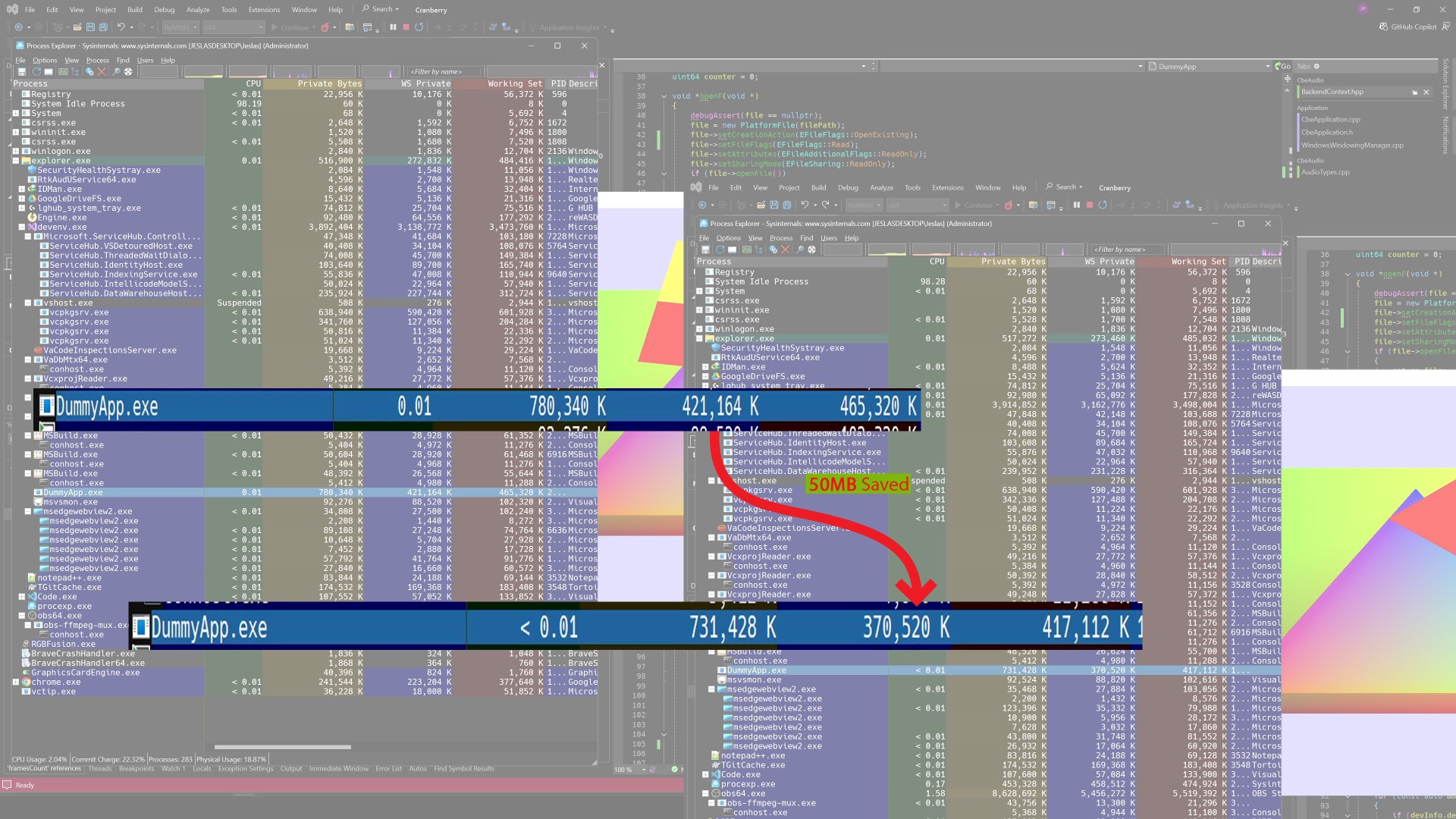
For a 150Seconds audio the streaming saves around 50MB of active memory.
Sound Graph
Attention Work in progress

Comments